This movie shows one way of thinking about an atom. In this atom, the electrons are yellow. They zip around the outer edges of the atom. In the middle of the atom is the nucleus. It has protons (red) and neutrons (blue). Each proton and electron has an electrical charge. A proton has a positive (+) charge. An electron has a negative () charge. This movie isn't quite the right scale for real atom. The electrons should be much smaller than the protons and neutrons. The electrons should also be much, much further away from the nucleus. If the nucleus was this size, the electrons would zing around in a space larger than a major sports stadium! An atom is mostly empty space. Original artwork by Windows to the Universe staff (Randy Russell).
An electron is a type of very, very tiny particle. Electrons, protons, and (usually) neutrons are the parts of an atom.
Electrons have a small electrical charge. Electrons have a negative (-) charge, while protons have a positive (+) charge. Neutrons don't have a charge.
Electrons are much smaller than protons and neutrons. Protons and neutrons are more than 1,800 time larger than electrons!
Protons and neutrons are in the nucleus of an atom, at its center. Electrons zing around the nucleus, sort of like high speed planets orbiting a star.
Sometimes electrons get knocked loose from their atom. They zip around through space at very high speeds. Sometimes they get speeded up even more by magnetic fields. Fast-moving electrons are a type of particle
radiation.
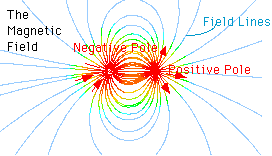
The force of magnetism causes material to point along the direction the magnetic force points. Here's another picture of how this works. This picture shows where the magnetic poles of the Earth are to...more
Text for this level has not been written yet. Please see the "Intermediate" text for this page if you want to learn about this topic. To get to the "Intermediate" text, click on the blue "Intermediate"...more
Did you know that a lot of what happens in space physics has to do with the interaction of really tiny particles? These particles like protons and electrons are so tiny that you can't even see them with...more
Have you ever seen the Southern or Northern Lights? Did you know that other planets (besides Earth) have them too? Scientists call these cosmic light shows the "aurora". Saturn is one of the planets that...more
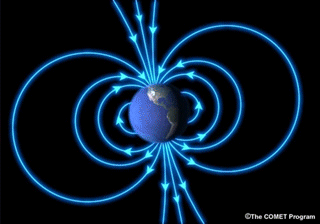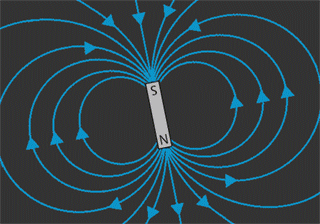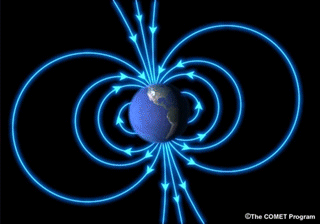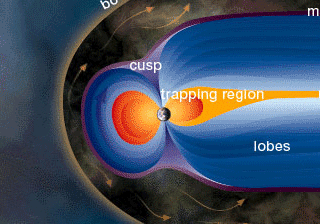
Earth has a magnetic field. If you imagine a gigantic bar magnet inside of Earth, you'll have a pretty good idea what Earth's magnetic field is shaped like. Of course, Earth DOESN'T have a giant bar magnet...more
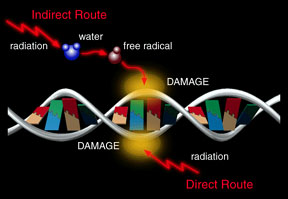
High frequency radiation or fast moving particles plow into a living cell with enough energy to knock electrons free from molecules that make up the cell. These molecules with missing electrons are called...more
Two scientists have discovered an easy way to get pure oxygen from water using a small amount of electricity. This discovery may become an important new green-energy source. To produce oxygen, they added...more


 Atomic Physics and Particle Physics
Atomic Physics and Particle Physics
 A Matter of Scale - interactive showing the sizes of things, from very tiny to huge - from NSF
A Matter of Scale - interactive showing the sizes of things, from very tiny to huge - from NSF